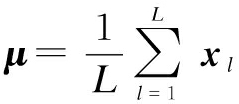
Abstract:To achieve efficient and compact low-dimensional features for speech emotion recognition, a novel feature reduction method using uncertain linear discriminant analysis is proposed. Using the same principles as for conventional linear discriminant analysis (LDA), uncertainties of the noisy or distorted input data are employed in order to estimate maximally discriminant directions. The effectiveness of the proposed uncertain LDA (ULDA) is demonstrated in the Uyghur speech emotion recognition task. The emotional features of Uyghur speech, especially, the fundamental frequency and formant, are analyzed in the collected emotional data. Then, ULDA is employed in dimensionality reduction of emotional features and better performance is achieved compared with other dimensionality reduction techniques. The speech emotion recognition of Uyghur is implemented by feeding the low-dimensional data to support vector machine (SVM) based on the proposed ULDA. The experimental results show that when employing an appropriate uncertainty estimation algorithm, uncertain LDA outperforms the conventional LDA counterpart on Uyghur speech emotion recognition.
Key words:Uyghur language; speech emotion corpus; pitch; formant; uncertain linear discriminant analysis (ULDA)
Speech is one of the most effective ways of humancomputer interaction in the era of artificial intelligence. Therefore, in the human-computer interaction system[1], in order to make the machine understand human emotion, the identification of the emotional state in the speech signal becomes increasingly important. Speech emotion recognition (SER) involves several different fields, including speech signal processing, pattern recognition, machine learning, psychology, and so on.
For SER, it is generally regarded as the default method for capturing paralinguistic information to generate a single high-dimensional representation of an utterance from a set of underlying low-level acoustic descriptors. Previous investigations consistently demonstrate the usefulness of this technique when applied to a range of different SER problems.
Dimensionality reduction is frequently used in the pre-processing stage to make the input data more suitable for modeling. Linear discriminant analysis (LDA)[2] is one of the simplest and most popular transforms to enhance class separability for multi-dimensional observations. Conventional LDA assumes that each class follows a normal distribution and classes share the same covariance structure. Although these assumptions do not generally hold in practice, the conventional approach and its variants have been found useful in many applications including automatic speech and speaker recognition. When the dimensionality of the data becomes comparable with the number of samples per class, the sample covariance estimation becomes unstable. Regularization and Bayesian estimation of covariance models have been discussed in exiting literature to overcome this issue. It is also possible to obtain a nonlinear class separation using subclass discriminant analysis and the kernel trick in LDA. When each class is composed of several partitions, subclass discriminant analysis aims to maximize the distance between the class means and the subclass means in the same class at the same time.
Compared to the principal component analysis (PCA)[3], class-dependent dimensionality reduction is expected to be more effective in modeling classes. The extension of LDA includes heteroscedastic LDA, quadratic discriminant analysis, and mixture discriminant analysis. A distance preserving dimensionality reduction transform maps the D-dimensional data samples to a d-dimensional space (d<D), which means that nearby data samples are mapped to nearby low-dimensional representations. Considering K as the number of the classes in a dataset, the selection of less than K-1 dimensions in LDA for data projection does not guarantee preserving the distance between classes from a classification perspective for K>2.
In this paper, we address the task of finding linear discriminant directions, using a probabilistic description instead of a point-estimation for an observation. We achieve such a probabilistic description by using so-called observation uncertainties. In this approach, the feature extraction process outputs the point-estimation of a feature vector along with an uncertainty. The point-estimation is assumed to form a Gaussian mean, while the corresponding variance is set as the estimated uncertainty. Throughout this paper, we note this process as an uncertain observation. Accordingly, we utilize uncertain LDA (ULDA)[4] to account for the observation uncertainties in estimating scatter matrices for LDA.
Based on the Uyghur speech emotion database, we set up a benchmark for Uyghur speech emotion recognition which involves a set of SER tasks in various training/test conditions. Additionally, the dimensionality reduction technique ULDA (uncertain linear discriminant analysis) is applied. We provide the complete data description, system architecture, experimental set-up and evaluation performance. These can be used as a full reference for Uyghur speech emotion recognition research.
Dimensionality reduction techniques are widely applied in speech emotion recognition research, such as PCA, LDA, locality preserving projections (LPP)[5], local discriminant embedding (LDE)[6], graph-based Fisher analysis (GbFA)[7] and so on. It is important to note that these methods do not solve recognition and hypothesis testing problems directly, and they are used as a pre-processing stage to reduce dimensionality. A conventional SER task requires a large number of features; hence, we should use an efficient dimensionality reduction technique to deal with this high-dimensional case. In this paper, we applied uncertain linear discriminant analysis (ULDA) to dimensionality reduction.
Let X=x1,x2,…, xL be a set of L samples (features), each sample belonging to one of K classes and partitioning the data into clusters C1, C2,…, CK. The conventional LDA aims at finding a linear transformation of those features that can maximize the separability of the clusters. Each class is assumed to be Gaussian distributed and has the same Gaussian covariance structure. In order to find the discriminant directions, we first calculate the sample mean μ and class mean μk as
(1)
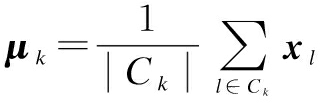
(2)
where ![]() is the cardinality of class k. Next, the within-class SW and between-class scatters SB are given as
is the cardinality of class k. Next, the within-class SW and between-class scatters SB are given as

(3)

(4)
The optimization problem is then solved by maximizing the Fisher-Rao criterion[1-3]as
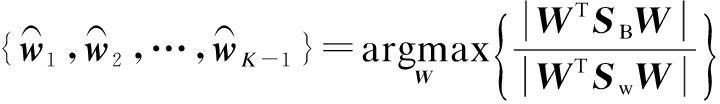
(5)
where ![]() (i=1,2,…, K-1) is the i-th eigenvector corresponding to the i-th eigenvalue λi, which is obtained by solving (SB-λiSW)
(i=1,2,…, K-1) is the i-th eigenvector corresponding to the i-th eigenvalue λi, which is obtained by solving (SB-λiSW)![]() =0. The optimal projection matrix W* is formed by putting d eigenvectors (d≤K-1) corresponding to the largest eigenvalues together and the new representation of features is given by
=0. The optimal projection matrix W* is formed by putting d eigenvectors (d≤K-1) corresponding to the largest eigenvalues together and the new representation of features is given by
Y=W*TX
(6)
where Y=y1,y2,…,yL.
ULDA is proposed for the case that the input data is available in the form of posterior distributions as X=x1, x2, …,xL, where each xl∈RD is described by a respective probability density function fxl|I(xl) with I as the available information. The conventional LDA can deal with this type of data by only using the first-order statistics as xl=μl=E(xl) and continue to calculate between- and within-class scatter matrices SB and SW. ULDA is developed in such a way that uses the second-order statistics of xl I). This claim is tested by the application of speech emotion recognition in this paper. In the following, we describe how to find expected scatter matrices.
I). This claim is tested by the application of speech emotion recognition in this paper. In the following, we describe how to find expected scatter matrices.
For the sake of tractability, we assume that posterior distributions of observations are Gaussian as xl|I~N(μl,Σl), which can be fully described by the first- and second-order statistics. In the following derivations, we rely on the fact that the sum of Gaussian variables is another Gaussian variable. By applying this principle, we obtain
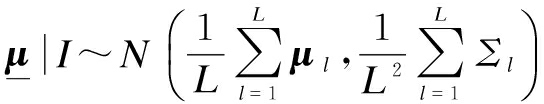
(7)

(8)
Next, we find the distribution for the sample mean deviation δlk, and the class mean deviation δk as
δlk=xl-μk⟹δlk|I~N(E(δlk), cov(δlk, δlk))
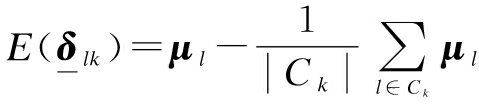

(9)
δk=μk-μ⟹δlk|I~N(E(δk), cov(δk,δk))

(10)

where we need to take into account the correlation between the mean and each sample. To calculate ![]() and
and ![]() , we just need to apply the linearity of the expectation operator so that
, we just need to apply the linearity of the expectation operator so that
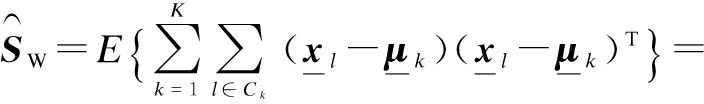


(11)

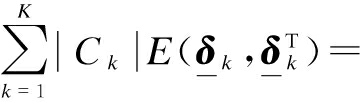

(12)
leading to
![]() δlk, δlk)=
δlk, δlk)=

(13)
![]() δk, δk)=
δk, δk)=

(14)
By removing uncertainties, i.e., setting Σl=0, the posterior description of features becomes a Dirac delta function centered on xl and hence ![]() =SB and
=SB and ![]() =SW.
=SW.
By using ![]() and
and ![]() in Eq.(5), the ULDA transform is found to be
in Eq.(5), the ULDA transform is found to be ![]() and the low-dimensional uncertain observations Y=y1,y2,…,yL are obtained by Eq.(6) with
and the low-dimensional uncertain observations Y=y1,y2,…,yL are obtained by Eq.(6) with ![]() replacing W*. All yl∈Rd(d<D) are then passed to the next steps of the classifier.
replacing W*. All yl∈Rd(d<D) are then passed to the next steps of the classifier.
At the INTERSPEECH conference, the Berlin Institute of Technology published a German language emotional speech database EMO-DB[8]. McGilloway et al.[9] recorded the Belfast emotional database. The Institute of Automation of Chinese Academy of Sciences published a Chinese speech emotion database CASIA. However, these related works have not focused on investigating emotion recognition in Uyghur speech. The Uyghur language is mainly used in Xinjiang, the Uyghur autonomous region of China. It is one of the most important minority languages of China. The Uyghur language belongs to the Altaic Turkic family of the west Hungarian branch, and its grammatical structure belongs to agglutinative type[10]. In view of this research gap, this paper established a Uyghur language speech emotion database (UYGSE-DB). The database has been collected and tagged with six basic emotional states, such as neutral, angry, happy, fear, sadness, and surprise.
The Uyghur language is agglutinative and syllabic in nature, which means that each syllable contains a vowel and is surrounded by consonants. Most Uyghur syllables occur in the pattern [CC]V[CC], where consonants can vary from zero to two. A word can be formed using one or more syllable. The agglutinative nature of Uyghur results in many different patterns that create many lexical variations. Each word may consist of a stem or root, and one or more suffixes in different combinations, resulting in a very systematic but complicated morphology. Uyghur is a one letter one pronunciation language which is not common in English. For example, the alphabet “b” is not pronounced in word “debt” in English, but such a case would not appear in Uyghur. So, Uyghur has a high level of transcriptional ambiguity.
The emotional corpus is the basis of speech emotion analysis, and the quality of the database directly affects all aspects of the recognition system, such as feature extraction and emotion modeling. In this paper, we collected the Uyghur emotional speech and made an Uyghur speech emotion database. Ten native Uyghur speakers (5 female and 5 male) simulated six emotions, producing 10 Uyghur utterances (frequently used sentences in daily life) which are interpretable in all applied emotions. This database contains 600 sentences(six emotions×ten speakers×ten sentences). The collection step is shown in Fig.1.
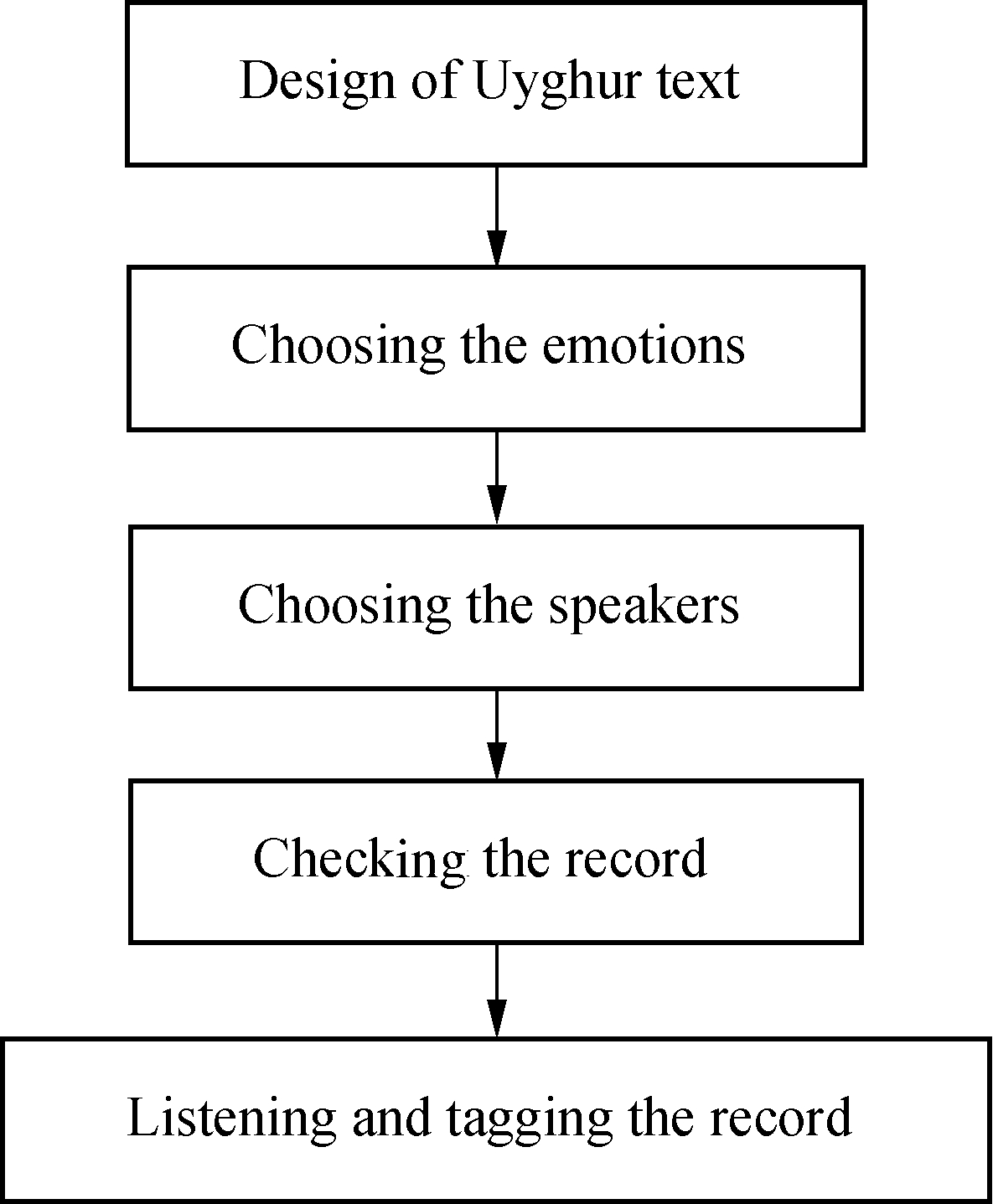
Fig.1 The flowchart of emotional speech data collection
Our emotional corpus is collected by the acting of emotions. First, we design the non-emotional tendency text (10 sentences) as shown in Tab.1. The UYGSE-DB was recorded by native Uyghur students with six target emotions. Considering the gap of the different gender’s expression of emotion, we select 5 female and 5 male performers in the recording. The performers are twenty to thirty-five years old.
Tab.1 Part of the Uyghur text

TextnumberUyghursentencesEnglishsentences1Nokidding!2Whatdoyouneed?3Itissnowingtoday.4Weneedhelp5Erkiniscoming.
The collected target emotions include six basic emotions: happy, sadness, fear, surprise, anger, and neutral. These six basic emotions are widely used in other corpus, such as EMO-DB and CASIA[11]. We collected and produced the corpus with six kinds of emotion, which is conducive to the future of cross language comparison study.
We chose the recording environment in a quiet laboratory. Hardware devices for recording include a high performance computer, a SONY recording pen, a listening headset, etc. The recording set-up is single channel, 16 bit sampling accuracy, 48 kHz sampling rate and PCM encoding. In each recording, data validity was checked and recorded once again instead of the poor quality voice. In order to correct tagging of the emotion class, we chose another ten native Uyghur listeners to distinguish the emotional class of the utterances, and the average listening ear recognition rate reached 93.7% and the confusion matrix is shown in Fig.2.
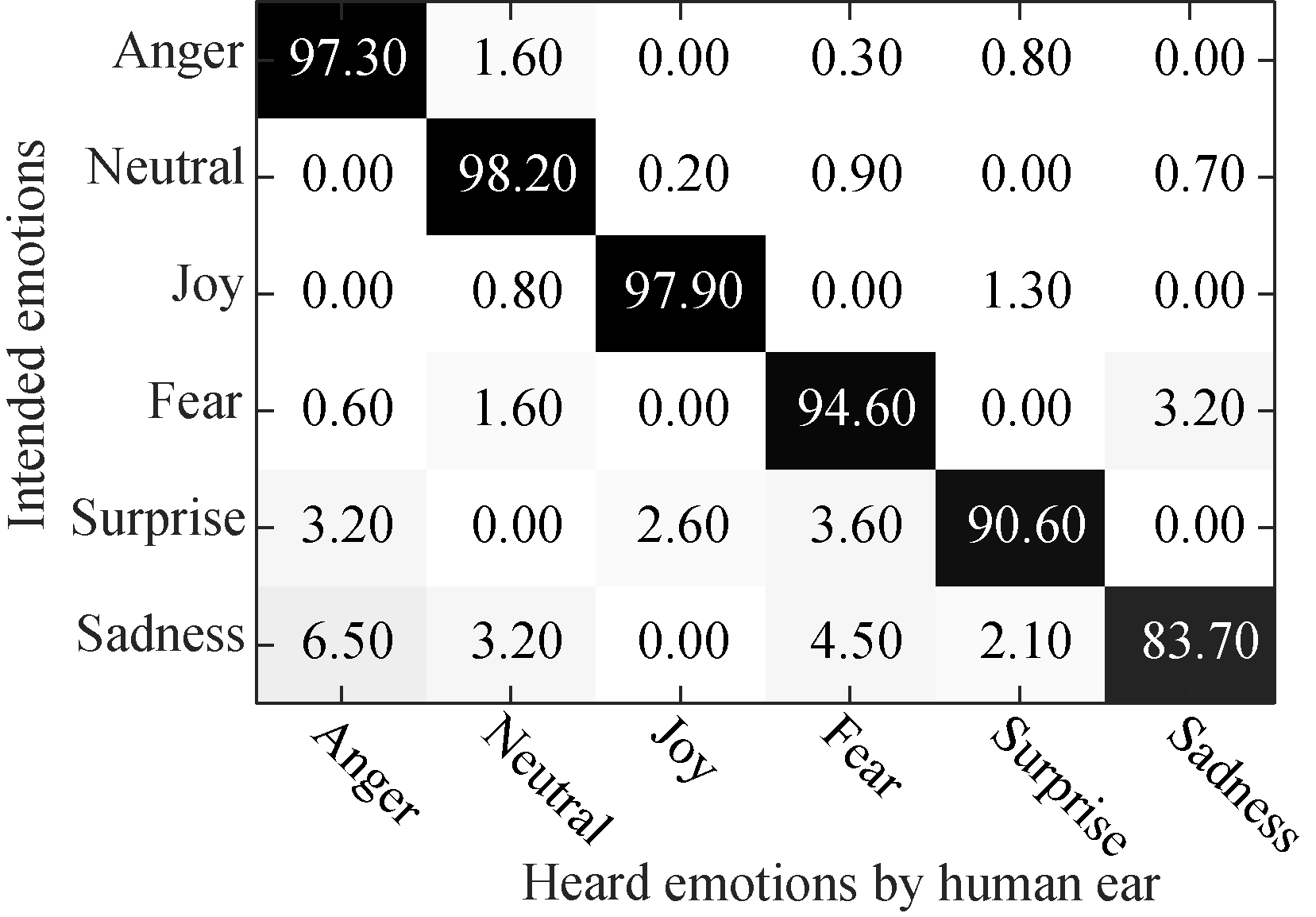
Fig.2 Confusion matrix of Uyghur speech emotion recognition in listening experiment
In this paper, we use the Hamming window to segment the speech signal into frames. In order to maintain the smoothness between frames, we set half of the frame length for overlapping.
In the time domain, waveform can also be found in the characteristics of Uyghur speech emotions, which is shown in Fig.3. Happy emotion speech has a short duration time and faster speech rate than neutral in Uyghur speech using the same text. The variation of sound intensity is also distinguished by the emotional state.
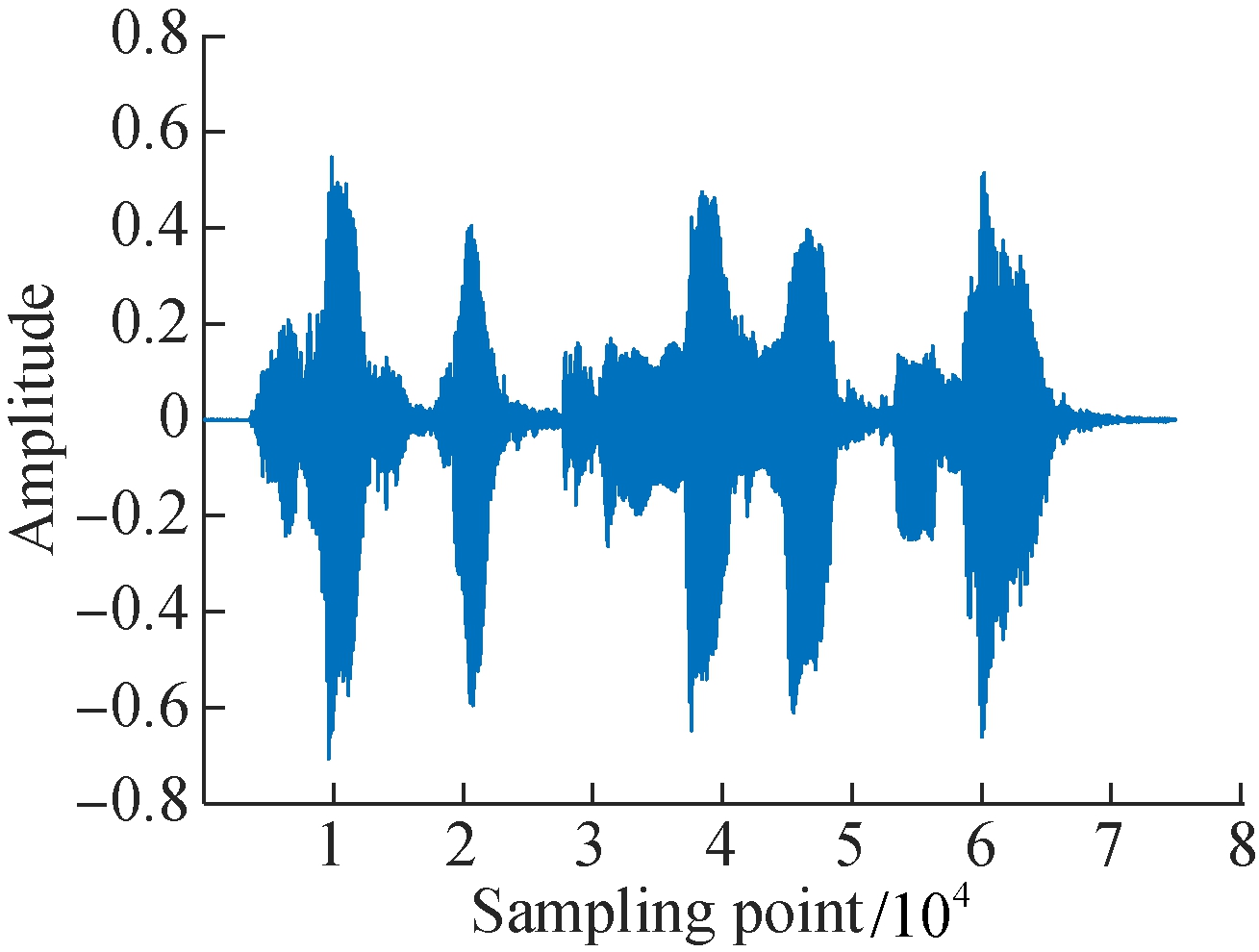


(a) (b) (c)

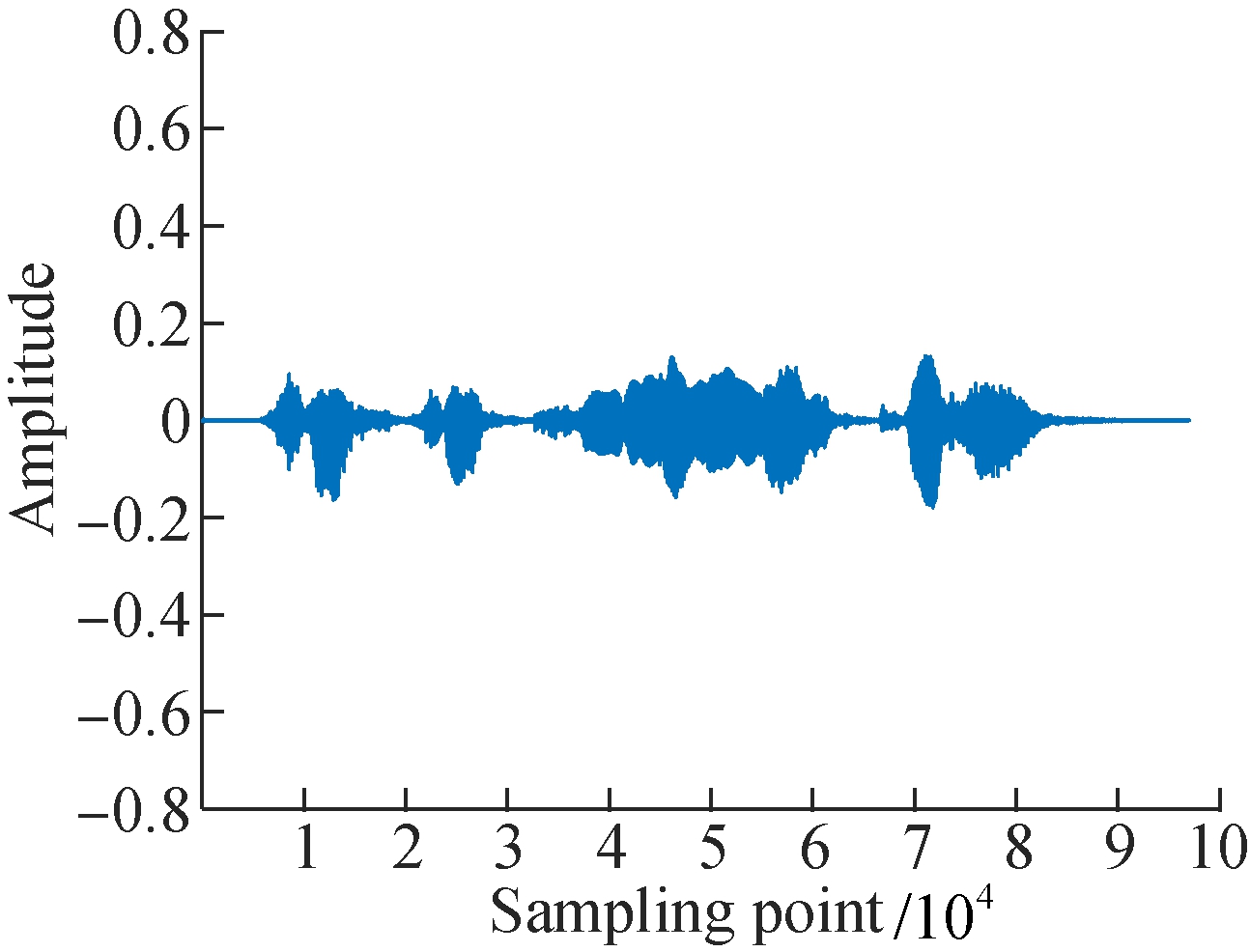

(d) (e) (f)
Fig.3 Comparison of the time-domain waveform under six emotions on Uyghur. (a) Anger; (b) Fear; (c) Happy; (d) Neutral;(e) Sadness; (f) Surprise
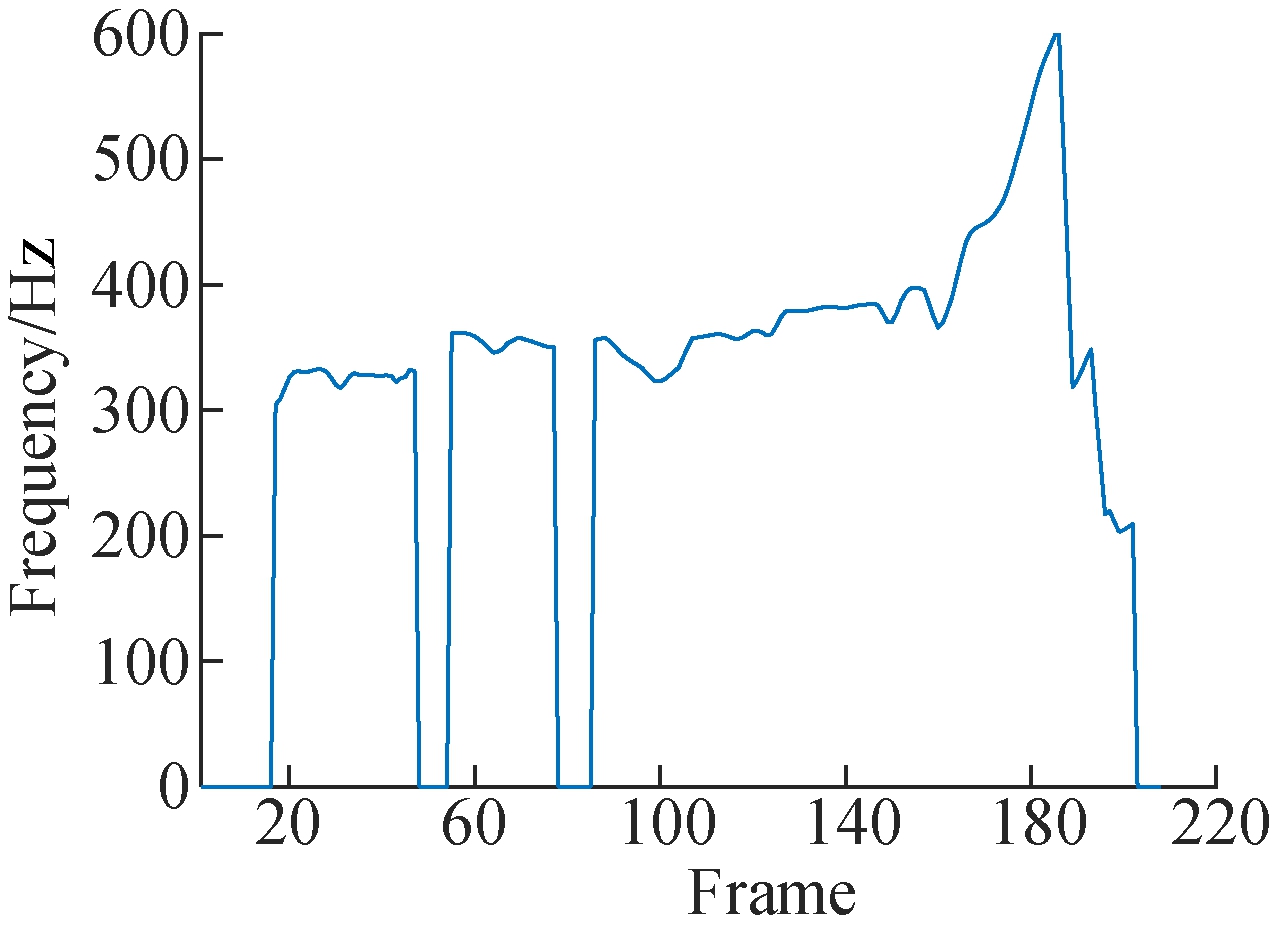
Fundamental frequency (pitch) is one of the most important speech characteristics. F0 is related to the vocal cord and it reflects the emotional changes of human voices. We analyze the F0 feature on the same Uyghur text, as shown in Fig.4. From the figure, we can find that the F0 feature is effective for acquiring emotional information in Uyghur speech. In addition, we fixed the contents of the Uyghur text, thus excluding the effects by phonemes. It is clearly observed from each F0 curve for different emotions that compared with neutral and sadness, the F0 curves of anger, fear, surprise and happy vary within a wide range.



(a) (b) (c)

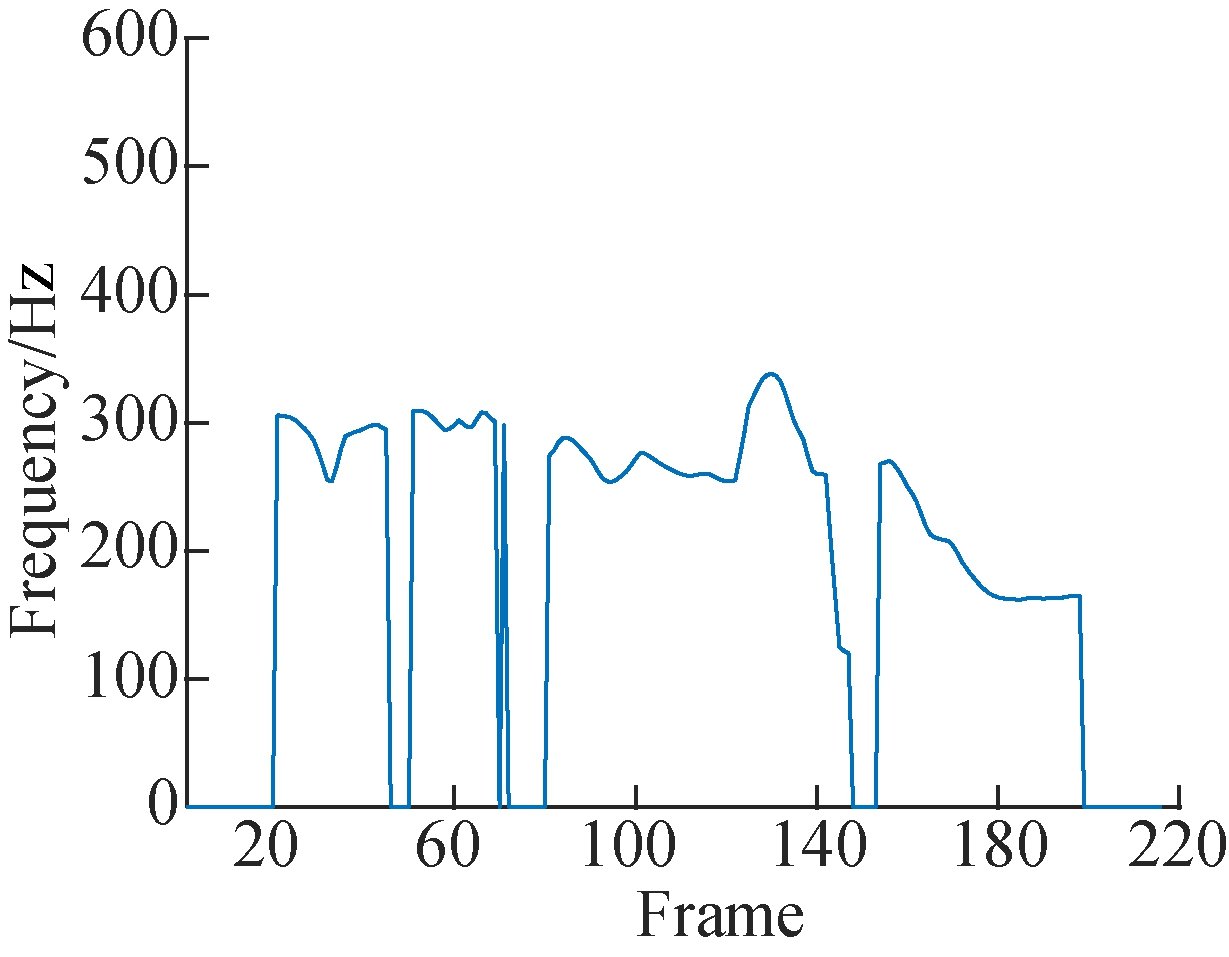
(d) (e) (f)
Fig.4 The variation of the pitch contour under six emotions on Uyghur. (a) Anger; (b) Fear; (c) Happy; (d) Neutral; (e) Sadness; (f) Surprise
The formant frequency is an important acoustic feature. It is widely used in speech recognition and speaker verification. Therefore, we analyze the 1st, 2nd, 3rd and 4th formant of Uyghur emotional speech signals. Then we can perceive that each emotion has different formant distribution in Uyghur emotional speech.
In general, prosodic and formant related features can reflect the emotional variation on Uyghur language. Thus, it is a more effective feature to distinguish the emotions in speech.
However, a variety of languages and cultures will bring some differences. Referring to the domestic and foreign research on the speech emotion recognition, we use 998 features to represent the emotions in the Uyghur speech emotion corpus.
Fig.5 shows each step of the Uyghur speech emotion recognition task. First, the open-source openSMILE toolbox[12] is used for feature extraction. The features are extracted as 19 functionals and 26 acoustics low-level descriptor (LLD)[13] with the first-order difference and second-order difference, and the total number of features is 988 (26×19×2), as shown in Tab.2 and Tab.3.
To guarantee speaker independence, the whole data set is separated into 10 parts according to 10 speakers (five female and five male). At each time step, 4 speakers (two female and two male) are left for testing and the other 6 speakers are combined for training and form a 9-fold cross-validation[14].
The ULDA dimensionality reduction algorithm shows better performance compared with other techniques such as PCA and conventional LDA. The best average recognition accuracy on the Uyghur six emotion classification task was achieved using the ULDA+SVM algorithm, as shown in Tab.4.

Fig.5 Flowchart of the Uyghur speech emotion recognition system
Tab.2 Acoustic descriptors
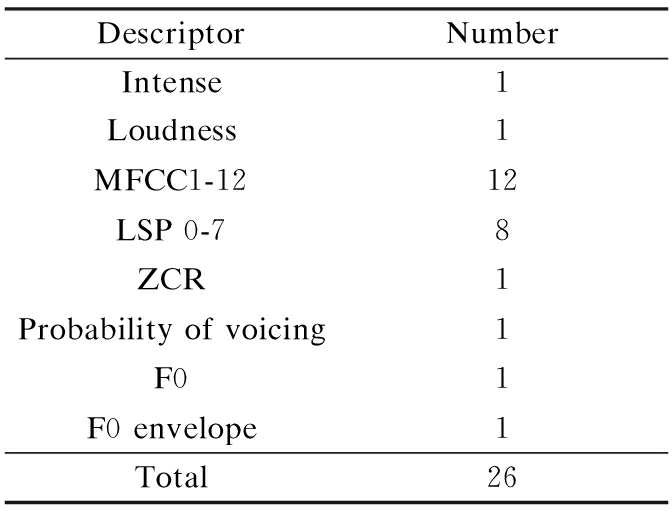
DescriptorNumberIntense1Loudness1MFCC1-1212LSP0-78ZCR1Probabilityofvoicing1F01F0envelope1Total26
Tab.3 Statistical functionals

FunctionalsNumberMax,min,andrange3Relativepositionofmaxandmin2Arithmeticmean1Linearregressioncoefficientsandcorrespondingappoximateerror4Standarddeviation,skewness,kurtosis3Quartilesandinter-quartileranges6Total19
Tab.4 Average recognition accuracy on Uyghur speech emotion database
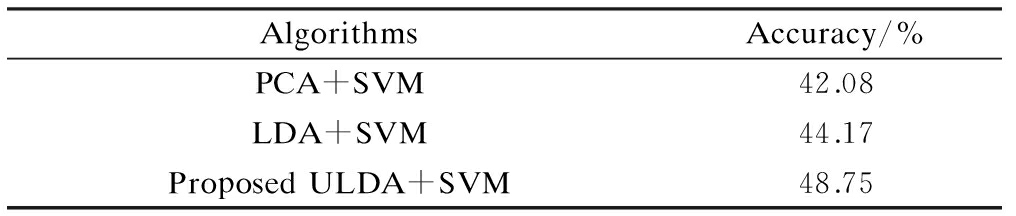
AlgorithmsAccuracy/%PCA+SVM42.08LDA+SVM44.17ProposedULDA+SVM48.75
In this paper, we present a Uyghur emotional database with basic emotions to analyze the emotional states in Uyghur speech. The emotional utterances are produced by Uyghur native speakers. Then, we propose a novel approach for coping with observation uncertainties in deriving an optimal linear discriminant feature transform. This so-termed uncertain LDA takes the probabilistic description of observations into account in finding the most discriminant directions. Compared to the existing algorithms, the proposed ULDA can effectively represent the emotional features in Uyghur speech. Our experiments indicate that by employing an appropriate uncertainty definition and a reliable uncertainty estimator, the Uyghur speech emotion recognition can be improved further when equipped with uncertain LDA.
References
[1]El Ayadi M, Kamel M S, Karray F. Survey on speech emotion recognition: Features, classification schemes, and databases [J]. Pattern Recognition, 2011, 44(3): 572-587. DOI:10.1016/j.patcog.2010.09.020.
[2]Chu D, Liao L Z, Ng M K, et al. Incremental linear discriminant analysis: A fast algorithm and comparisons [J]. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(11): 2716-2735. DOI:10.1109/TNNLS.2015.2391201.
[3]Quan C, Wan D, Zhang B, et al. Reduce the dimensions of emotional features by principal component analysis for speech emotion recognition [C]//Proceedings of the 2013 IEEE/SICE International Symposium on System Integration. Kobe, Japan, 2013: 222-226. DOI:10.1109/sii.2013.6776653.
[4]Saeidi R, Astudillo R F, Kolossa D. Uncertain LDA: Including observation uncertainties in discriminative transforms [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(7): 1479-1488. DOI:10.1016/j.patcog.2010.09.020.
[5]Soldera J, Behaine C A R, Scharcanski J. Customized orthogonal locality preserving projections with soft-margin maximization for face recognition [J]. IEEE Transactions on Instrumentation and Measurement, 2015, 64(9): 2417-2426. DOI:10.1109/TIM.2015.2415012.
[6]Zhou Y, Peng J, Chen C L P. Dimension reduction using spatial and spectral regularized local discriminant embedding for hyperspectral image classification [J]. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(2): 1082-1095.
[7]Li W, Du Q. Laplacian regularized collaborative graph for discriminant analysis of hyperspectral imagery [J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(12): 7066-7076. DOI:10.1109/tgrs.2016.2594848.
[8]Burkhardt F, Paeschke A, Rolfes M, et al. A database of German emotional speech [C]//Proceedings of the 2005 INTERSPEECH. Lisbon, Portugal, 2005:1517-1520.
[9]McGilloway S, Cowie R, Douglas-Cowie E, et al. Approaching automatic recognition of emotion from voice: A rough benchmark [C]//Proceedings of the 2000 ISCA Workshop on Speech and Emotion: A Conceptual Framework for Research. Newcastle, Northern Ireland, UK, 2000:207-212.
[10]Ablimit M, Eli M, Kawahara T. Partly supervised Uyghur morpheme segmentation [C]//Oriental Committee for the Co-ordination and Standardization of Speech Databases and Assessment Techniques Workshop. Kyoto, Japan, 2008: 71-76.
[11]Pan S, Tao J, Li Y. The CASIA audio emotion recognition method for audio/visual emotion challenge 2011 [C]//Affective Computing and Intelligent Interaction Fourth International Conference. Memphis, USA, 2011:388-395. DOI:10.1007/978-3-642-24571-8_50.
[12]Eyben F, Wollmer M, Schuller B. Opensmile: The munich versatile and fast open-source audio feature extractor [C]//ACM International Conference on Multimedia. Firenze, Italy, 2010: 1459-1462.
[13]Xu X Z, Deng J, Zheng W M, et al. Dimensionality reduction for speech emotion features by multiscale kernels [C]//Proceedings of Annual Conference of the International Speech Communication Association. Dresden, Germany,2015:1532-1536.
[14]Wu S, Falk T H, Chan W Y. Automatic speech emotion recognition using modulation spectral features [J]. Speech Communication, 2011, 53(5): 768-785. DOI:10.1016/j.specom.2010.08.013.
摘要:为了在语音情感识别中获得高效、紧凑的低维特征,提出了一种新的基于不确定线性判别分析的特征约简方法.用与传统LDA相同的原则,在最大判别方向的估计中引入带噪声或失真输入数据的不确定性.在维吾尔语语音情感识别任务上验证了不确定性判别分析的有效性.在该情感数据上,分析了维吾尔语的语音情感特征,着重对维吾尔语语音的基音频率和共振峰频率进行了详细分析.利用不确定性线性判别分析对特征维数进行了降维研究,获得了比其他的常用降维技术更好的结果.通过不确定性线性判别分析获得的低维数据供给支持向量机,实现了维吾尔语的语音情感识别.实验结果表明,采用适当的不确定性估计算法时,在维吾尔语音情感识别任务上,不确定性线性判别分析(ULDA)算法优于传统LDA降维算法.
关键词:维吾尔语;语音情感数据库;基音频率;共振峰;不确定性线性判别分析
中图分类号:TP391
DOI:10.3969/j.issn.1003-7985.2017.04.008
Received 2017-05-17,
Revised 2017-08-30.
Biographies:Tashpolat Nizamidin (1988—), male, graduate; Zhao Li (corresponding author), male, doctor, professor, zhaoli@seu.edu.cn.
Foundation item:The National Natural Science Foundation of China (No.61673108, 61231002).
Citation:Tashpolat Nizamidin, Zhao Li, Zhang Mingyang, et al. Emotion recognition of Uyghur speech using uncertain linear discriminant analysis[J].Journal of Southeast University (English Edition),2017,33(4):437-443.
DOI:10.3969/j.issn.1003-7985.2017.04.008.